Extracting large amounts of data
By Niek Tettero
Help!? I want to extract a large amount of data
This blog post is for anyone who would like to use the flempar package to extract large amounts of data over multiple years from the Flemish Parliament’s API and use it for analysis. By walking you through several code examples, I illustrate how to use flempar to construct a dataset suitable for analysis.
Prerequisites
To follow along with the code discussed in this post, you need the following packages; flempar, dplyr, tidyr, tibble, purr, data.table, and lubridate. Consequently, you would have to have a basic understanding of R, the dplyr package and flempar. To familiarize yourself with the functions flempar offers, please read the introductory blog posts.
Preparatory work
In this post, I will show how to collect a large amount of data to perform sentiment analysis on oral questions and interpellations in the plenary sessions of the Flemish Parliament over the past 4 years using the flempar package. Some endpoints in the API are limited to processing 10000 pages per call. Therefore, it is not always possible to extract all data from 4 years in one go. Nevertheless, dividing these tasks for shorter periods is a more sensible approach. Collecting all data at once may take some time. If the operation stops because of an error, we lose all our progress and need to start over. By dividing the task, we ensure the collected data is stored correctly. In case of any errors, we can start where we left off.
As we are collecting a ton of data that must be combined in the last stages, keeping everything well organized is key. To do this, create a folder called data. In this data folder, create two more folders called speech and details. We will be using these folders to write the collected data to. Then in R start your script by defining these paths. This way you can follow along with the tutorial below.
path_speech <- "C:/Users/you/data"
path_details <- "C:/Users/you/data"
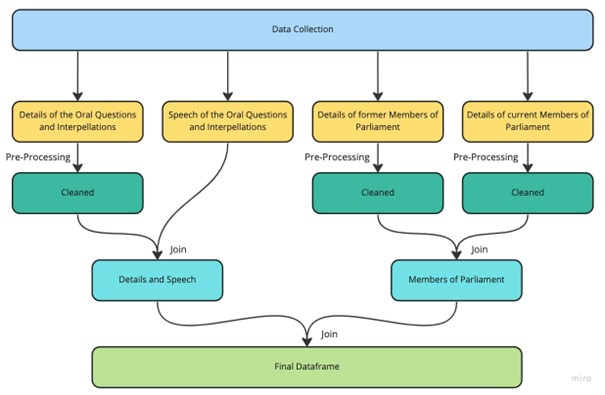
The flowchart below presents the step-by-step approach from data collection to the final data frame. The data collection results in four data frames. To three of them, some preprocessing steps are applied to end up with cleaned data frames. The cleaned data frames with all the information concerning current and former members of parliament are joined together. The same applies to the details and speech data frames of the oral questions and interpellations. The final step is joining the details and speech data frame with the members of parliament data frame.
To automate the data collection process, a data frame consisting of all start and end dates is needed. You can play with the length of the intervals in your date data frame. In this case, half-year intervals, specifically 182 days, will suffice. The collection of other data could require a shorter interval to not run into the limits of the API.
data.frame(datum_start = seq(ymd("2018-01-01"),
ymd("2022-12-31"),
by = 182)) %>%
mutate(datum_end = lead(datum_start-1, default = ymd("2022-12-31"))) -> date
For this period, the result is a data frame of 11 rows. The last row represents a concise time interval as the last included date is set to finish at a default 2022-12-31.
Note that you can easily collect data from a longer period (e.g. the past 20 years) by simply widening the interval in the data frame.
Collecting data
After specifying the path variables, we use a for loop to extract the data for all time intervals. The loop iterates over the number of rows of the date data frame and writes the result of the get_work function for the period specified in each row to a variable defined in the for loop called output. If the get_work function fails, we only risk losing one iteration.
Step by step, this function works as follows. In the try function, we execute the get_work function. If everything goes well, the function retrieves the data. The if statement is used to detect any errors in the get_work function. If the output of get_work is of the class try-error, the Sys.sleep function is activated and puts the loop to sleep (first 60 seconds, then two minutes, followed by 30 minutes). If the output class is still a try-error after sleeping for a total of 33 minutes, the loop is stopped. Worst case scenario, the connection to the API does not come about after 33 minutes, and the loop stops.
If no errors occur, saveRDS saves the output as an rds file in the location specified in the path variable. An rds file is R’s own data file format that allows it to preserve data types of columns. It also takes up less memory than a CSV file and retains the data types (like character and numeric). Using a path, we can save the outputs in a predetermined folder.
To retrieve the session details, we use the same structure, only changing the parameter of the type argument of the get_work function to details and the path.
for(i in 1:nrow(date)){
output <- try({
get_work(date_range_from=date$datum_start[[i]]
,date_range_to=date$datum_end[[i]]
,type="speech"
,fact="oral_questions_and_interpellations"
,plen_comm="plen")
})
if(any(stringr::str_detect(tolower(output[1]),"no sessions found"))){
next()
}
if(any(class(output) == "try-error")){
message("error, will sleep for 1 minute")
Sys.sleep(60)
message("slept for 1 minute, let's retry")
try({
get_work(date_range_from=date$datum_start[[i]]
,date_range_to=date$datum_end[[i]]
,type="speech"
,fact="oral_questions_and_interpellations"
,plen_comm="plen")
})}
if(any(class(output) == "try-error")){
message("another error, will sleep for 2 minutes")
Sys.sleep(2*60)
message("slept for 2 minutes, let's retry")
try({
get_work(date_range_from=date$datum_start[[i]]
,date_range_to=date$datum_end[[i]]
,type="speech"
,fact="oral_questions_and_interpellations"
,plen_comm="plen")
})}
if(any(class(output) == "try-error")){
message("another error, powernap of 15 minutes")
Sys.sleep(15*60)
message("slept for 15 minutes, let's try one more time")
try({
get_work(date_range_from=date$datum_start[[i]]
,date_range_to=date$datum_end[[i]]
,type="speech"
,fact="oral_questions_and_interpellations"
,plen_comm="plen")
})}
if(any(class(output) == "try-error")){
stop()
message("function stopped")
}
saveRDS(output, paste0(path_speech,date$datum_start[[i]],".rds"))
message(i,"/",nrow(date))
}
Combining retrieved data into data frames
If all goes well, our data folder contains 11 rds files for every time interval in the four years. In the code below, we use the list.files and map_dfr functions to join the rds files stored in our folder to one data frame. list.files produces a character vector of all the file names in the specified directory. Using map_dfr, we return a data frame created by row binding all separate rds files.
oral_questions_and_interpellations <- list.files(path = path_speech
,pattern = "*.rds", full.names = TRUE ) %>%
map_dfr(readRDS)
The result is a data frame that includes all speech fragments of the oral questions and interpellations. This data frame has 55611 rows and four variables: journaallijn_id, text, sprekertitel, and persoon_id. Each row represents a speech fragment stored in the text column. The journaallijn_id refers to the id given to each interaction (question and answer), the sprekertitel, and the persoon_id, which includes the unique id of the speaker.
length(unique(oral_questions_and_interpellations$persoon_id))
Over the whole period, there have been 211 unique speakers, most of whom are parliament members, but the speakers also include the chairman and the ministers. When written as a CSV file, this data frame is 24.8 MB.
The session’s details are extracted using the same for loop but by changing the type argument to details instead of speech. Additionally, you must change the path.
for(i in 1:nrow(date)){
output <- try({
get_work(date_range_from=date$datum_start[[i]]
,date_range_to=date$datum_end[[i]]
,type="details"
,fact="oral_questions_and_interpellations"
,plen_comm="plen")
})
if(any(stringr::str_detect(tolower(output[1]),"no sessions found"))){
next()
}
if(any(class(output) == "try-error")){
message("error, will sleep for 1 minute")
Sys.sleep(60)
message("slept for 1 minute, let's retry")
try({
get_work(date_range_from=date$datum_start[[i]]
,date_range_to=date$datum_end[[i]]
,type="details"
,fact="oral_questions_and_interpellations"
,plen_comm="plen")
})}
if(any(class(output) == "try-error")){
message("another error, will sleep for 2 minutes")
Sys.sleep(2*60)
message("slept for 2 minutes, let's retry")
try({
get_work(date_range_from=date$datum_start[[i]]
,date_range_to=date$datum_end[[i]]
,type="details"
,fact="oral_questions_and_interpellations"
,plen_comm="plen")
})}
if(any(class(output) == "try-error")){
message("another error, powernap of 15 minutes")
Sys.sleep(15*60)
message("slept for 15 minutes, let's try one more time")
try({
get_work(date_range_from=date$datum_start[[i]]
,date_range_to=date$datum_end[[i]]
,type="details"
,fact="oral_questions_and_interpellations"
,plen_comm="plen")
})}
if(any(class(output) == "try-error")){
stop()
message("function stopped")
}
saveRDS(output, paste0(path_details,date$datum_start[[i]],".rds"))
message(i,"/",nrow(date))
}
However, combining the resulting rds files into a data frame, including all ‘session details’, requires a bit more attention. Not all output might not have the same columns or column names. Therefore, we need a different approach. The method works as follows. First, we define a variable called path. The fs::dir_ls function returns file names as named fs_path character vectors. These are used to create a list with the length of the number of files in our directory. Then we use a for loop to iterate over the files in the directory we specified in the path variable. Next, we read all files with readRDS. The variables we need are selected and stored in the list. Note that, using the mutate function, we create a variable formatted as year-month-day. The rationale for this will become evident later. Lastly, we bind the list to end up with a data frame.
path <- fs::dir_ls(path_details) #~/test_flemparblog_data/details/
list <- vector(mode="list",length= length(path))
for(i in seq_along(path)){
readRDS(path[[i]]) %>%
select(verg_id, datum=datumbegin, journaallijn_id, id_fact) %>%
mutate(datum = as.Date(datum, format = "%Y-%m-%d")) -> list[[i]]
}
details <- rbindlist(list)
Now, the details data frame can be joined with the data frame containing all the text of the oral questions and interpellations.
oral_questions_and_interpellations %>%
left_join(details, by = c(“id_fact” = id_fact)) -> oqai_details
Members of Parliament (MP)
All MPs have a unique id that can be linked to their personal information. As discussed in the Retrieving members of parliament blog, the get_mp function allows us to extract the personal information of all the MPs.
Extracting information on current and former MPs is very straightforward. One thing to notice is the use of the raw parameter. By selecting this parameter, the function returns all the data available in the API without preprocessing. This includes the parliamentarians’ current and former party membership.
If the parameter is not specified as raw, the function only outputs the current or most recent information. Since we are interested in a period that extends the current parliamentary year and several MPs have switched parties over time, we need a workaround. The raw parameter provides this workaround as the output now includes current and former party memberships. Later, we will use this information to join the correct information to the oral questions and interpellations.
current <- get_mp(selection="current"
, fact="raw")
former <- get_mp(selection="former"
,fact="raw")
Although the code is straightforward, this call returns many data, which is also quite messy. We find ourselves in a data frame-ception with data frames nested within several variables. These variables need to be unnested to display the data we need correctly. For this, we use the code fragment below. This shows the main advantage of flempar: the amount of preprocessing it does when other parameters are used.
The first line turns our data frame into a tibble where every variable starts with ‘vv’. This ‘vv’ helps to unnest all the nested variables in one go, avoiding the hassle of specifying each variable that needs to be unnested. The next step is to select the variables we need. This could vary depending on what data you need, so please look at all the variables included; there might be some you would like to use that we did not include. Depending on which variables you select, additional unnesting steps are necessary. Some variables, such as huidigefractie hold multiple values, such as party_id, colour, the link to the party logo, the name, and the number of seats in parliament. More unnesting is needed to give each value its own variable. The same approach holds for other variables that include multiple values.
current %>%
tibble::tibble(vv = .) %>%
tidyr::unnest_wider(vv) %>%
dplyr::select(id_mp=id,voornaam, achternaam=naam,geslacht,geboortedatum,geboorteplaats,huidigefractie,lidmaatschap) %>%
tidyr::unnest_wider(huidigefractie, names_sep="_") %>%
tidyr::unnest_wider(huidigefractie_1, names_sep="_") %>%
tidyr::unnest_wider(lidmaatschap, names_sep="_") %>%
tidyr::unnest(lidmaatschap_1) %>%
tidyr::unnest(c( fractie)) %>%
dplyr::select(id_mp,voornaam, achternaam,geslacht,geboortedatum,geboorteplaats,party_id_current=huidigefractie_1_id,party_naam_current = huidigefractie_1_naam,naam,datumVan,datumTot, zetel_aantal = ,`zetel-aantal`) %>%
dplyr::mutate(geboortedatum = lubridate::date(lubridate::ymd_hms(geboortedatum))) -> current_clean
former %>%
tibble::tibble(vv = .) %>%
tidyr::unnest_wider(vv) %>%
dplyr::select(id_mp=id,voornaam, achternaam=naam,geslacht,geboortedatum,geboorteplaats,huidigefractie,lidmaatschap) %>%
tidyr::unnest_wider(huidigefractie, names_sep="_") %>%
tidyr::unnest_wider(huidigefractie_1, names_sep="_") %>%
tidyr::unnest_wider(lidmaatschap, names_sep="_") %>%
tidyr::unnest(lidmaatschap_1) %>%
tidyr::unnest(c( fractie)) %>%
dplyr::select(id_mp,voornaam, achternaam,geslacht,geboortedatum,geboorteplaats,party_id_current=huidigefractie_1_id,party_naam_current = huidigefractie_1_naam,naam,datumVan,datumTot,zetel_aantal =`zetel-aantal`) %>%
dplyr::mutate(geboortedatum = lubridate::date(lubridate::ymd_hms(geboortedatum))) -> former_clean
This results in a ‘current_cleaned’ dataframe with 285 observations and 12 columns and a ‘former_cleaned’ dataframe with 2778 observations and 12 columns.
Note that the Flemish Parliament has 124 members and the current_cleaned data frame has 285 observations. Some MPs occur more than once because they have, for instance, been part of different political parties over time. This could either be because parties have switched names or merged, or because the MP has actually switched parties.
This final step binds the cleaned data frames together.
mp <- rbind(current_clean,former_clean)
Joining MP info with facts
We encounter an issue if we want to combine the MP information with our oral question and interpellations data frame. As mentioned, several MPs have switched parties over time. To properly join the two data frames together, considering the party membership of the MP at the time of the oral question or interpellation, we need to blow up the MP data frame. The data frame created by the code below consists of the mp_id, the political party, and all the days the MP was a member of that party.
mp %>%
mutate(datumTot = as.Date(datumTot)) %>%
mutate(datumVan = as.Date(datumVan)) %>%
mutate(datumTot = if_else(is.na(datumTot), Sys.Date(), datumTot)) %>%
# sequence of monthly dates for each corresponding start, end elements
transmute(id_mp, voornaam, achternaam, geslacht, geboortedatum
, geboorteplaats, naam, zetel_aantal,
day = map2(datumVan, datumTot, seq, by = "1 day")) %>%
# unnest the list column
tidyr::unnest(cols = c(day)) %>%
# remove any duplicate rows
distinct -> id_mp_day
This is where the date (datum) variable of the details data frame comes in. Using a left_join, we can join the oral questions and interpellations data frame to MP data frame, joining them by date and id.
oqai_details %>%
left_join(id_mp_day, by = c('datum' = 'day', 'persoon_id' = 'id_mp')) -> final_df
There you go! You have a final data frame including all oral questions and interpellations from the Flemish Parliament’s plenary sessions over the last four years, including all speaker information necessary for further analysis. As mentioned, you can easily collect this data for 20 years using the same method.
Final remarks
- The
flemparpackage combined with R’stryfunction allows us to collect data over longer periods of time. - Using
dplyr, the data collected withflemparcan be preprocessed and combined to create useful data frames for analysis.